

Playbooks
Creating high-quality scorecards in Score AI is fundamental to successful AI-powered quality assurance. Well-defined scorecards enable accurate, consistent evaluation of customer interactions while also improving our automated AI coaching and feedback mechanisms.
In Score AI, scorecards are referred to as 'Playbooks'. Our AI QA system uses these playbooks to understand, replicate and automate your quality assurance process.
Anatomy of a Playbook
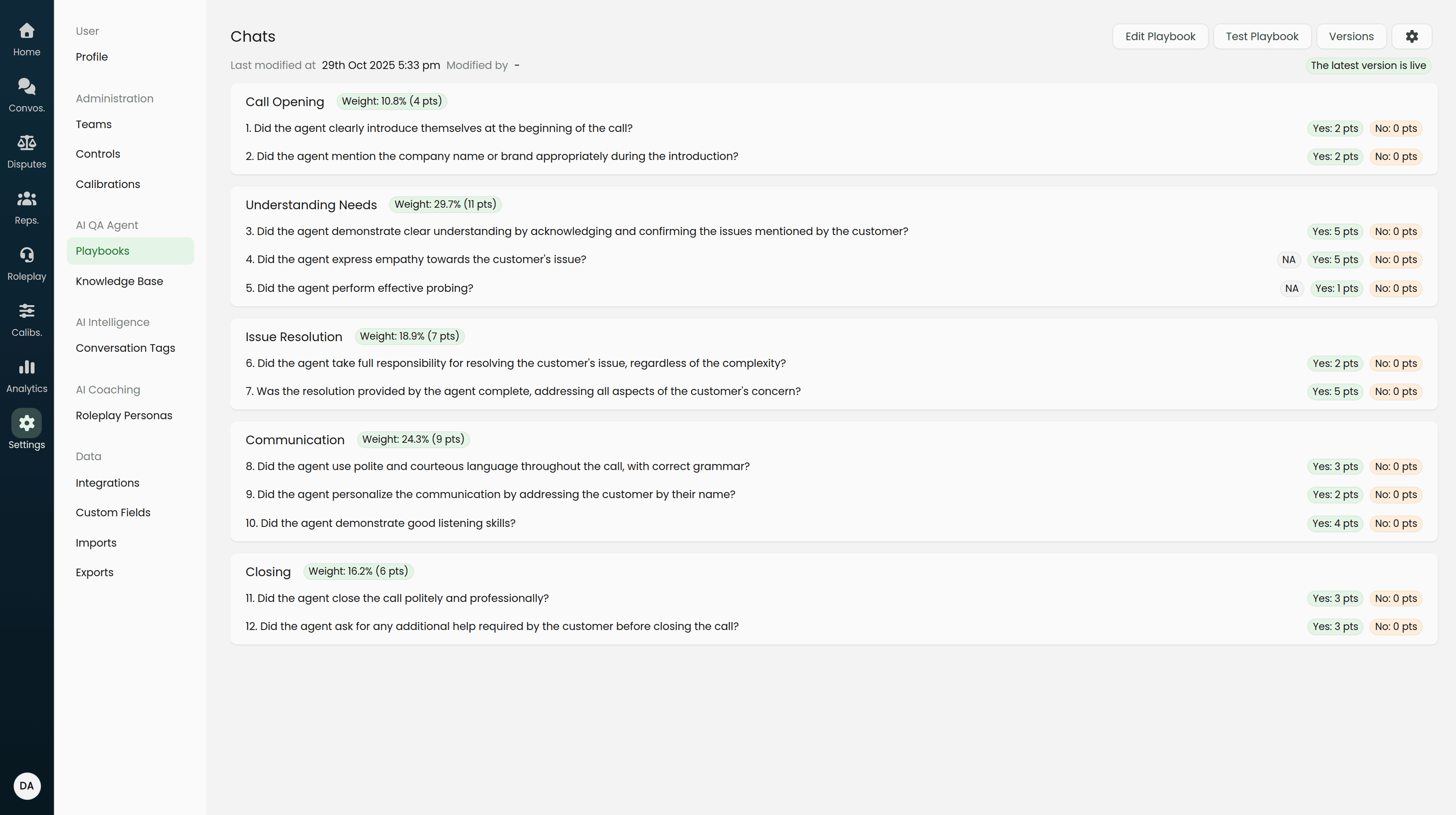
Parameters
Parameters are sections into which you can split your playbook. They are useful for grouping logically similar evaluation criteria into the same bucket — allowing us to provide analytics and identify coach-able opportunities for these buckets.

Evaluation Criteria
Criteria are the core building blocks of your Scorecards that assess a particular standard or action the representative should be following during or after a customer interaction.

Evaluation Method
To appropriately replicate your end-to-end QA process in Score AI, we offer a variety of evaluation techniques that inform our AI QA system how the criteria should be evaluated.
They are as follows:
Standards: Use this to evaluate language, behavior and content of interactions with the customer. For example, "Did the representative confirm the registered mobile number?".
Speech: Use this for evaluating pace, dead air and filler words. For example, "Did the representative talk above 200 words per minute in the second half of the call?"
Compliance: Use this for evaluating standard operating procedures and compliance using your knowledge base. For example, checking if the representative gave the correct refund turn-around-time based on the customer's payment mode.
Actions: Use this for evaluating post-interaction actions and escalations. For example, checking if the representative filled out a Google Form after the interaction was completed.
Question & Points
The question of each criterion is a short question to be posed to our AI QA system with respect to each customer interaction. This question should be appropriately contained to a single task that needs evaluation in a customer interaction.
Points assigned to each criterion count towards the final playbook score. More on playbook scoring here.
Advanced AI Settings
For an evaluation criterion where a simple question is unable to describe everything that needs to be audited as part of the criterion, we provide some more settings which can help you provide more context to the AI QA system.

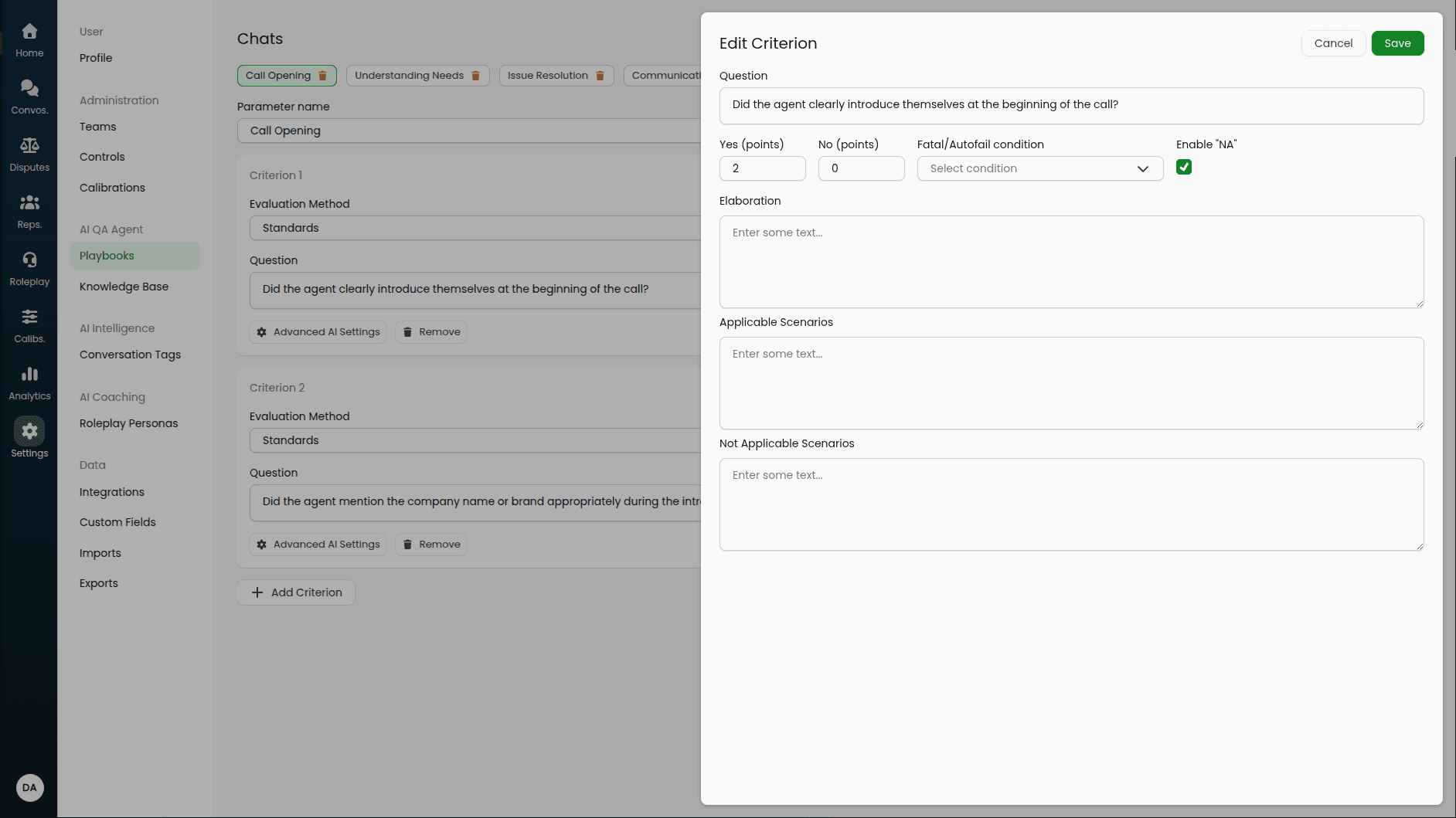
Elaboration
The elaboration field functions differently based on the "Evaluation Method" of the criterion.
Standards & Speech: An in-depth description of the criteria being evaluated. You can refer to our Elaboration Cheatsheet for writing AI-friendly elaborations for these evaluation methods.

Compliance & Actions: Usually not required unless there is a very specific way to identify relevant instructions in your knowledge base. In such situations, the elaborations on these criteria should ONLY have explanations of how to find relevant information in your knowledge base documentation and integrations while the actual instructions (compliance and procedures) should be found in the knowledge base.

Auto-fail / Fatal Condition
You can enable auto-failure of the playbook upon evaluation of a criterion to a specific value; Yes, No or NA. On auto-failure, the playbook's score will be set to 0% and the conversation along with the respective criterion will be flagged as "Fatal".
Applicability
Not all criteria are applicable to all types of conversations or scenarios. To tackle this, we provide the "Enable 'NA'" checkbox which will then reveal 2 new inputs: "Applicable Scenarios and "Not Applicable Scenarios".
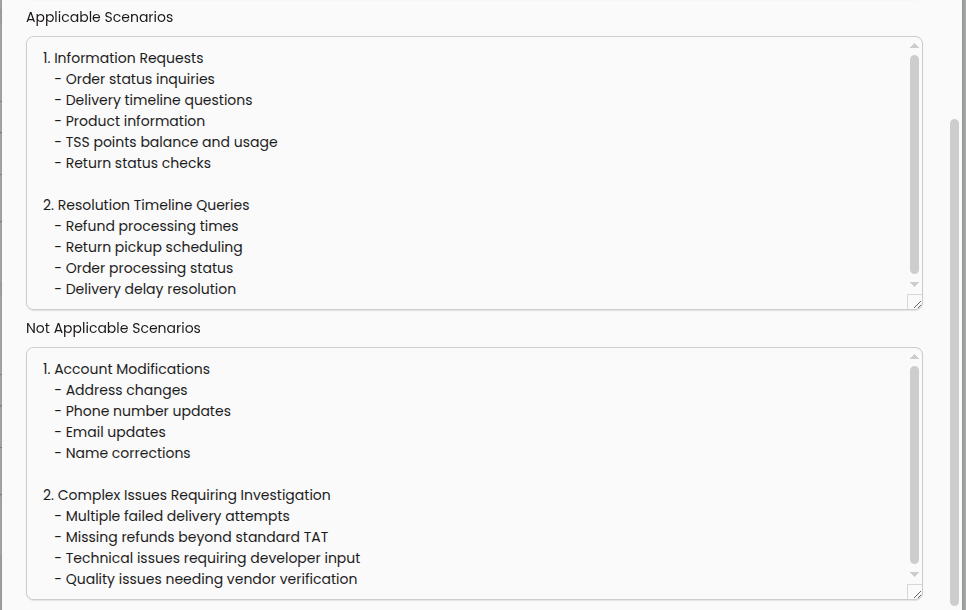
In both of these text boxes, you can describe in which situations the AI QA system should or should not mark the evaluation as "NA".
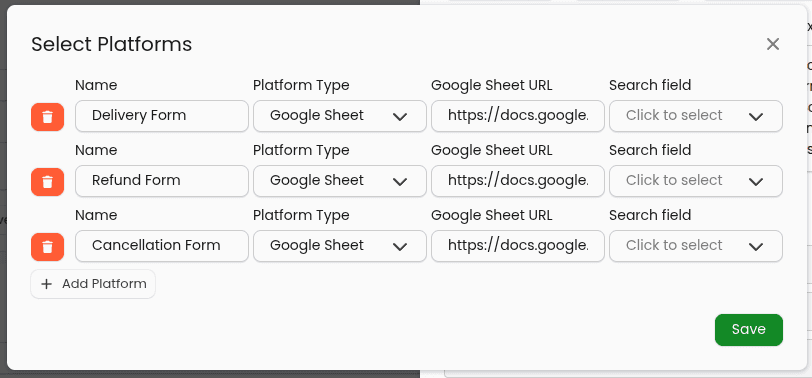
External Platforms (Actions Evaluation Method Only)
To evaluate actions performed by representatives on external platforms, you can provide a list of platforms for actions criteria.
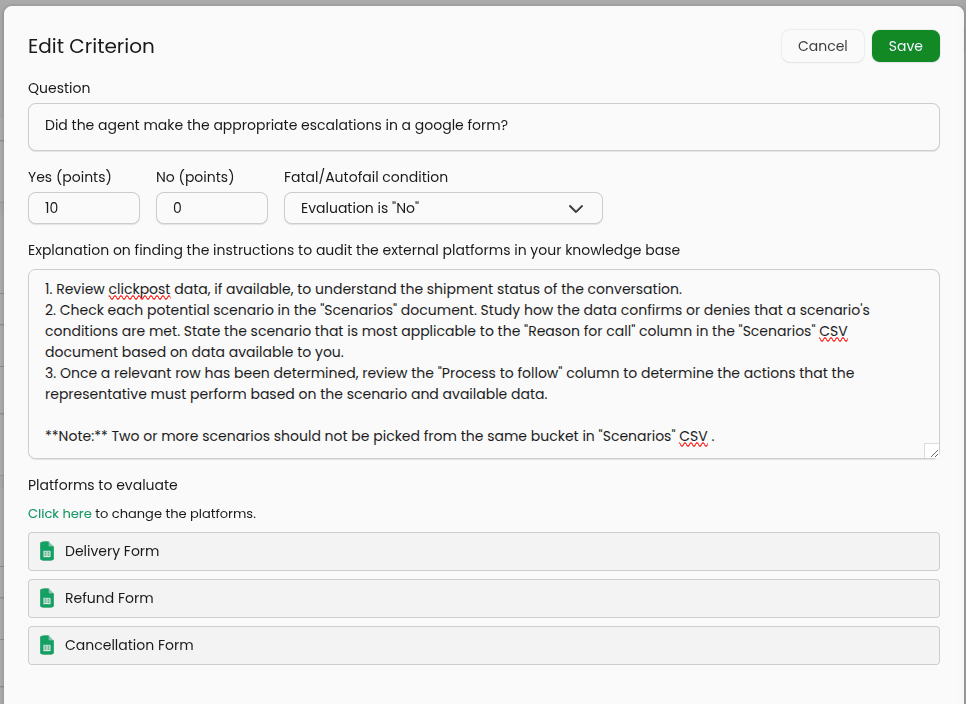
These platforms will be checked by the AI QA system using a predefined "search field" when auditing the conversation. To configure a platform, you will need to input the following properties:
Name: A name for the platform which matches whats written in your knowledge base. For example, if you have statements saying an entry should be made in the "Delivery form" then the name of the platform should also be "Delivery form". Exact matches are not required but be sure to not have names that might confuse the AI - especially duplicates!
Platform Type: The platform being audited — Currently we support Google Sheets (i.e., Google Forms).
For google sheets platform types you will need to provide the URL for the sheet as well as give "Viewer" access to a particular email address .
We actively work with our customers to add more platform types as per their requirements. Please reach out to support to request a platform that will be useful for you.Search field: A field present on your conversations (from your integration) that can be used to find data entries in the platform.
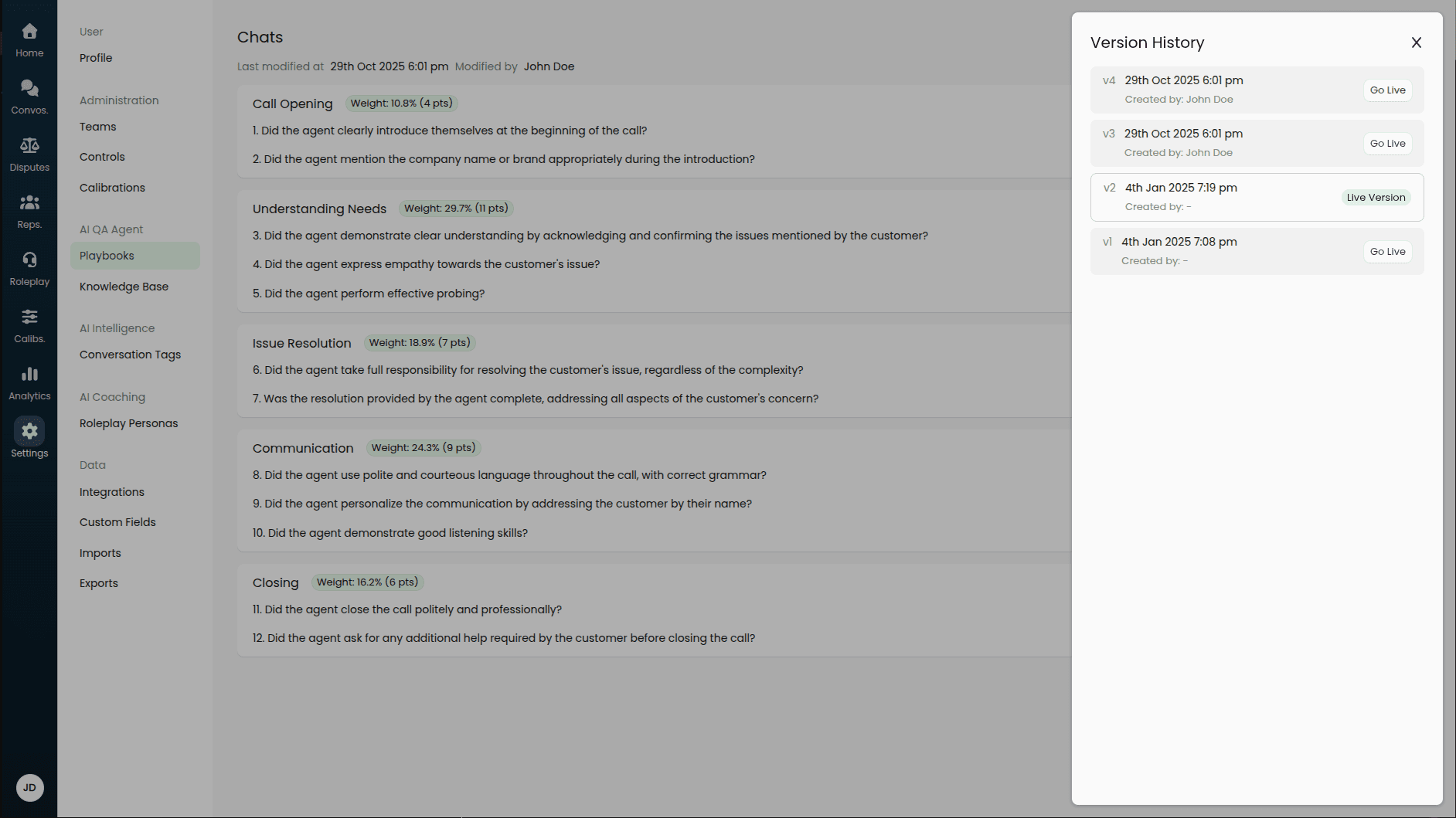
Versions
Internal processes change and scorecards need occasional updates. When managing your playbooks in Score, you will always have a "Live" version which may or may not be the most recently edited version of your playbook. This allows you to confidently save edits to your playbook(s) — knowing that it will not impact the evaluations of the conversations being actively audited.
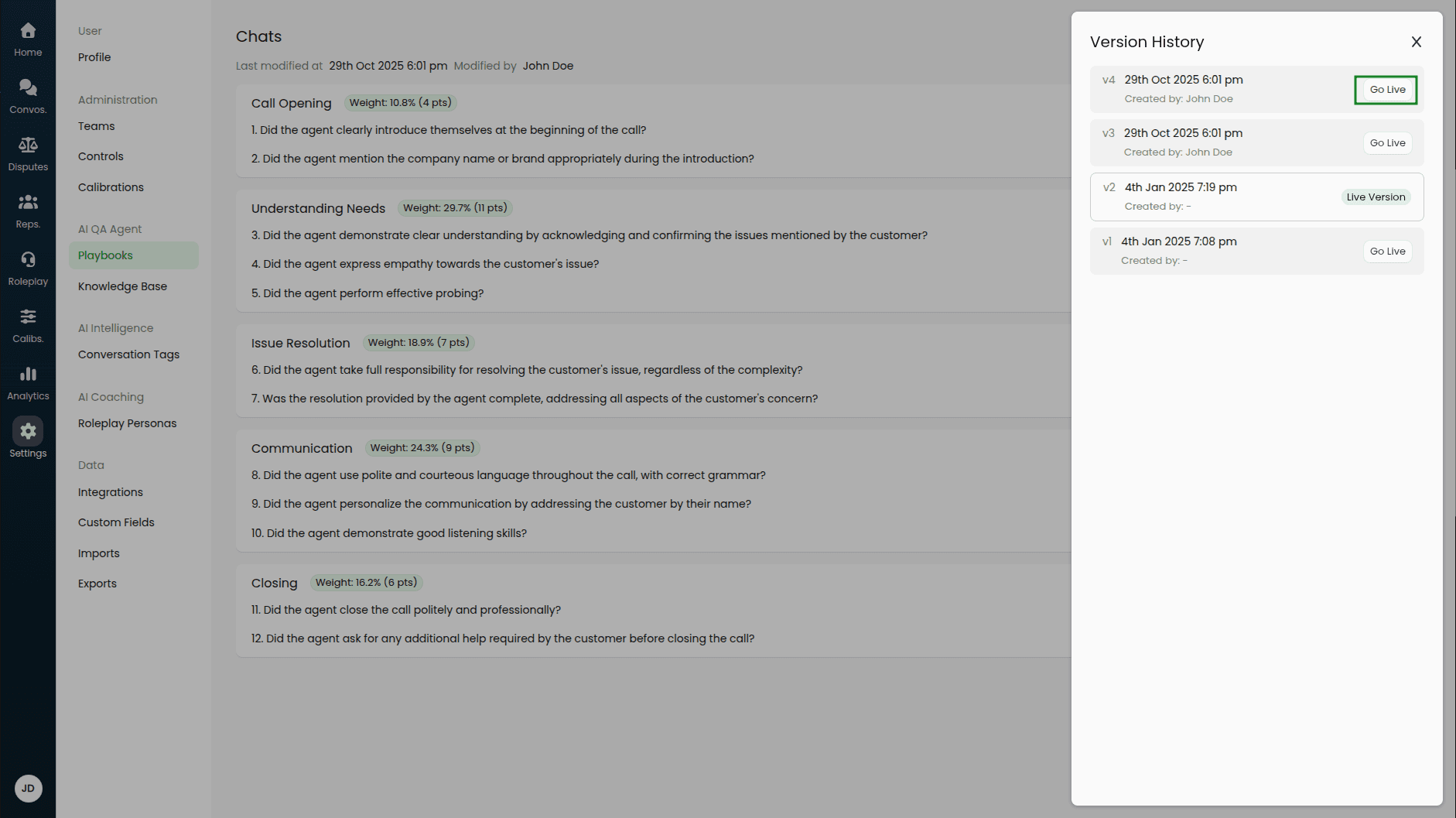
Playbook versions can be taken live when you are certain that all required changes have been saved and tested.
Testing
Playbook testing allows you to assign conversations as test cases for your playbook. You can run evaluations of playbooks against each conversation and be confident about changes to your playbook before you take them live.
Refer to our in-depth guide on playbook testing over here.
Settings
In the settings of each playbook you can rename playbooks and configure how playbooks are selected for conversations, using assignment rules.
Assignment Rules
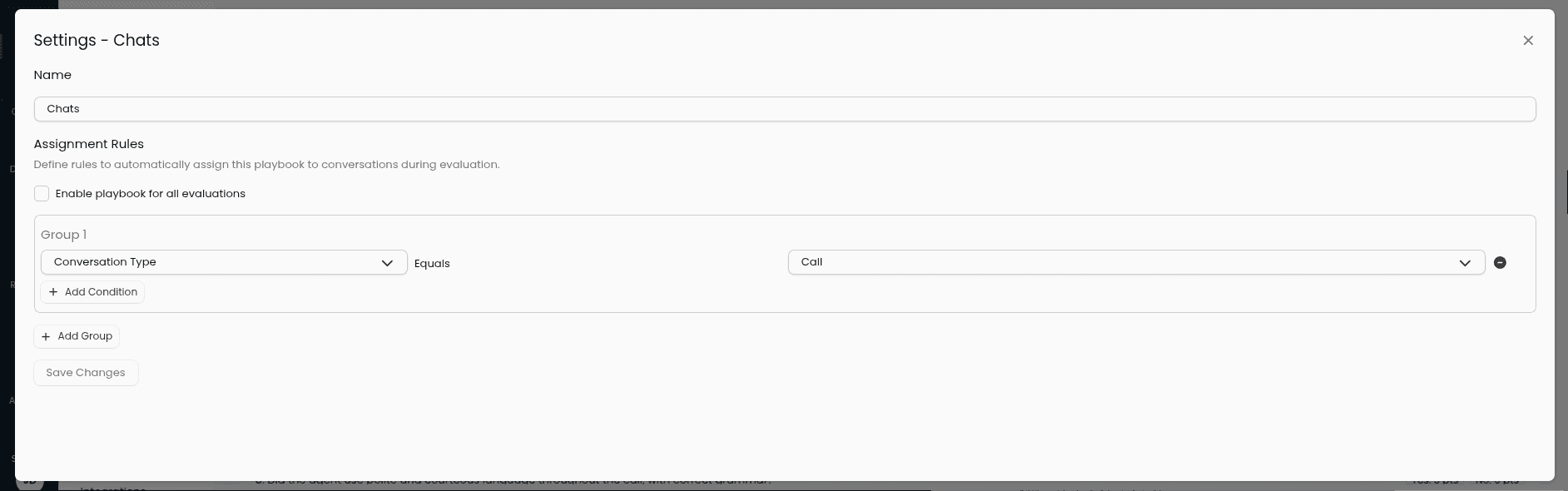
Assignment rules allow you to define conditions in which playbooks will be selected to be evaluated against conversations. The available fields are:
Conversation title
Conversation type
Conversation duration
Team name